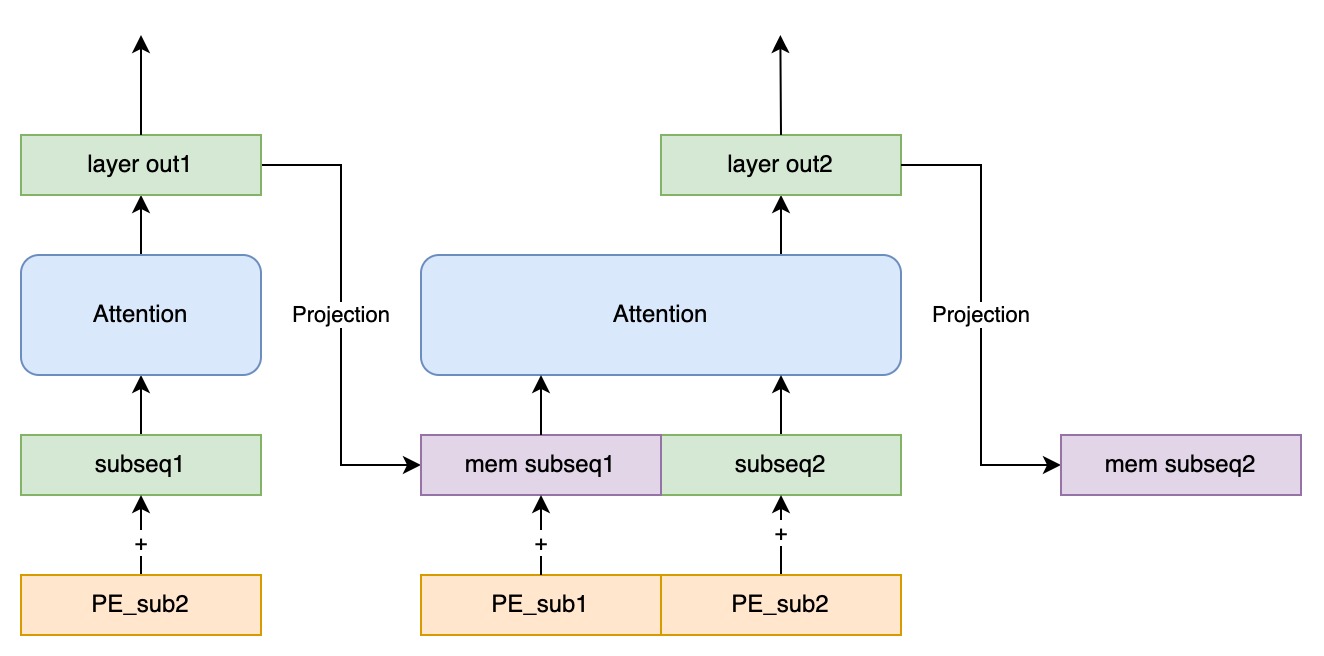
The Transformer architecture, especially in decoder-only form for autoregressive language modeling, has achieved remarkable success in natural language processing due to its powerful parallel capabilities and attention mechanism. However, the standard Transformer’s attention mechanism is stateless, which poses dual challenges of O(N^2) computational complexity and inference memory consumption when processing long texts. Existing solutions such as Transformer-XL introduce segment-level recurrence, but their state transfer is limited to direct copying of the KV cache, lacking deep state evolution, which restricts their theoretical receptive field to N x L. In this paper, we propose a Truncated Recurrent Transformer architecture. This architecture transforms the Transformer from a stateless parallel computer into a stateful sequence model by introducing an explicit Recurrent State. Our core innovations lie in: (1) Explicit State Evolution: introducing a non-linear projection (Projection FFN) between blocks, enabling memory to ’think’ and ’compress’ in the temporal dimension, rather than just being passively stored; and (2) Stateful Segment Training: combining the classic truncated backpropagation through time (TBPTT) idea from RNNs, maintaining state transfer across batches during training, enabling the model to learn true long-distance dependencies. Experimental results show that the model, trained on a length of only 256, can generalize to sequences of 4096 or even longer, with loss continuously decreasing as length increases (Train Short, Test Long), demonstrating effective length extrapolation.